코틀린으로 Spring Batch 도큐먼트 찍먹하기
예시
CSV 스프레드시트에서 데이터를 가져오고 이를 사용자 정의 코드로 변환하고 최종 결과를 데이터베이스에 저장하는 서비스를 구축하기
https://spring.io/guides/gs/batch-processing
Getting Started | Creating a Batch Service
A common paradigm in batch processing is to ingest data, transform it, and then pipe it out somewhere else. Here, you need to write a simple transformer that converts the names to uppercase. The following listing (from src/main/java/com/example/batchproces
spring.io
Person
@Getter
@Setter
class Person(var firstName: String = "", var lastName: String = ""){
override fun toString(): String {
return "{ firstName=$firstName, lastName=$lastName }"
}
}Step 만들기
Step은 Spring Batch에서 작업을 단계적으로 수행하는데 사용되는 개념이다. 일반적으로 배치 프로세스는 여러 단계로 구성되고, 각 단계는 특정 작업을 수행하고 필요한 전처리나 후처리를 할 수 있도록 설계한다.
Step의 특징
- 단위 작업:
Step은 배치 프로세스에서 실행되는 단위 작업을 나타낸다. 이 작업은 특정한 기능을 수행하거나 데이터를 처리하는 등의 역할을 한다. - 독립성: 각
Step은 독립적으로 실행될 수 있어야 한다. 즉, 각 Step은 다른 Step에 대한 의존성 없이 개별적으로 실행될 수 있어야 한다. - 재사용성:
Step은 일반적으로 여러 Job에서 재사용될 수 있는 단위로 설계된다. 따라서 유사한 작업이 필요한 경우 이를 재사용하여 코드의 중복을 피할 수 있다. - 전/후처리:
Step은 실행하기 전에 전처리 작업을 수행할 수 있으며, 실행 후에는 후처리 작업을 수행할 수 있다. 이는 Step 실행 전에 데이터를 초기화하거나Step실행 후에 결과를 정리하는 등의 작업에 사용된다. - 트랜잭션:
Step은 트랜잭션 내에서 실행된다. 따라서 각 Step의 실행은 성공 또는 실패로 완료되며, 이에 따라 롤백이나 재시도가 이루어진다.
Step
@Configuration
class BatchConfiguration {
@Bean
fun step1(
jobRepository: JobRepository,
transactionManager: DataSourceTransactionManager,
reader: FlatFileItemReader<Person>,
processor: PersonItemProcessor,
writer: JdbcBatchItemWriter<Person>
) : Step{
return StepBuilder("step1", jobRepository)
.chunk<Person, Person>(10, transactionManager)
.reader(reader)
.processor(processor)
.writer(writer)
.build()
}
//...
}- 이번 예제는
chunk단위로 step을 구성했다. chunk사이즈는10으로 10개 단위로 레코드를 처리한다.
ItemReader
ItemReader는 Spring Batch에서 데이터를 읽어오는 것을 추상화한 개념이다.
Spring Batch는 기본적으로 파일 포인터를 이용하여 데이터를 순차적으로 읽어오는 FlatFileItemReader, JDBCTemplate을 이용하여 데이터를 읽어오는 JdbcCursorItemReader(커서 기반), JdbcPagingItemReader(페이징 기반) 등의 구현체를 제공한다.
FlatFileItemReader
@Configuration
class BatchConfiguration {
@Bean
fun reader(): FlatFileItemReader<Person> {
return flatFileItemReader : FlatFileItemReader<Person> = FlatFileItemReaderBuilder<Person>()
.name("personItemReader")
.resource(ClassPathResource("sample-data.csv"))
.delimited()
.names("firstName", "lastName")
.targetType(Person::class.java)
.build()
}
//...
}ItemProcessor
ItemProcessor는, 입력 데이터를 가공하거나 변환하는 책임을 가진다. 즉 ItemReader로 부터 읽은 데이터를 처리하여 ItemWriter로 전달한다.
ItemProcessor 구현체
class PersonItemProcessor : ItemProcessor<Person, Person> {
val log = LoggerFactory.getLogger(PersonItemProcessor::class.java)
override fun process(person: Person): Person? {
val firstName: String = person.firstName.uppercase()
val lastName: String = person.lastName.uppercase()
val transformedPerson: Person = Person(firstName, lastName)
log.info("Converting ({}) into ({})", person, transformedPerson)
return transformedPerson
}
}
@Configuration
class BatchConfiguration {
@Bean
fun processor() : PersonItemProcessor {
return PersonItemProcessor()
}
//...
}ItemWriter
ItemWriter는 배치 작업의 마지막 단계에서 처리된 데이터를 저장하거나 출력하는 책임을 가진다.
SpringBatch는 기본적으로 JDBCTemplate을 이용하여 SQL 쿼리를 날려주는 JdbcBatchItemWriter, JPA 엔티티를 사용하여 영속화 시켜주는 JpaItemWriter, 파일로 IO 해주는 FlatFileITemWriter 등을 제공하고,
ItemWriter 인터페이스
이 구현체를 구현하여 직접 필요한 ItemWriter를 커스텀 할 수 있다.
@FunctionalInterface
public interface ItemWriter<T> {
void write(@NonNull Chunk<? extends T> chunk) throws Exception;
}JdbcBatchItemWriter 구현체
@Configuration
class BatchConfiguration {
@Bean
fun writer(dataSource: DataSource) : JdbcBatchItemWriter<Person> {
return JdbcBatchItemWriterBuilder<Person>()
.sql("insert into people (first_name, last_name) values (:firstName, :lastName)")
.dataSource(dataSource)
.beanMapped()
.build()
}
}Job
이렇게 Step, ItemReader, ItemProcessor, ItemWriter들을 모두 정의하였으면 가장 큰 단위인 Job을 정의할 때이다.
@Configuration
class BatchConfiguration {
@Bean
fun importUserJob(jobRepository: JobRepository, step1: Step, listener: JobCompletionNotificationListener) : Job {
return JobBuilder("importUserJob", jobRepository)
.listener(listener)
.start(step1)
.build()
}
// ...
}- JobExecutionListener **구현체를 listener에 지정하면 작업이 끝나고 실행할 콜백함수를 줄 수 있다.
ItemReader 수정
현재 chunk 단위를 10으로 해서 10개씩 데이터를 읽어, 처리한 다음, 쓰게 되는데 로그만 봤을 때는 10개씩 끊어서 보여주지 않기 때문에 chunk 단위로 잘 작업하는지 알 수 없다.
ItemReader 수정
@Configuration
class BatchConfiguration {
@Bean
fun reader(): FlatFileItemReader<Person> {
val flatFileItemReader : FlatFileItemReader<Person> = FlatFileItemReaderBuilder<Person>()
.name("personItemReader")
.resource(ClassPathResource("sample-data.csv"))
.delimited()
.names("firstName", "lastName")
.targetType(Person::class.java)
.build()
flatFileItemReader.setLineMapper(object : DefaultLineMapper<Person>() {
init {
setLineTokenizer(DelimitedLineTokenizer().apply {
setNames("firstName", "lastName")
})
setFieldSetMapper { fieldSet ->
val person = Person()
person.firstName = fieldSet.readString("firstName")
person.lastName = fieldSet.readString("lastName")
log.info("Reading line: {}", fieldSet)
person
}
}
})
return flatFileItemReader
}
// ...
}- 로그를 찍는
lineMapper를 수동으로 설정lineMapper는 SpringBatch에서 소스로 부터 읽어온 라인을 객체로 매핑하는데 사용한다.
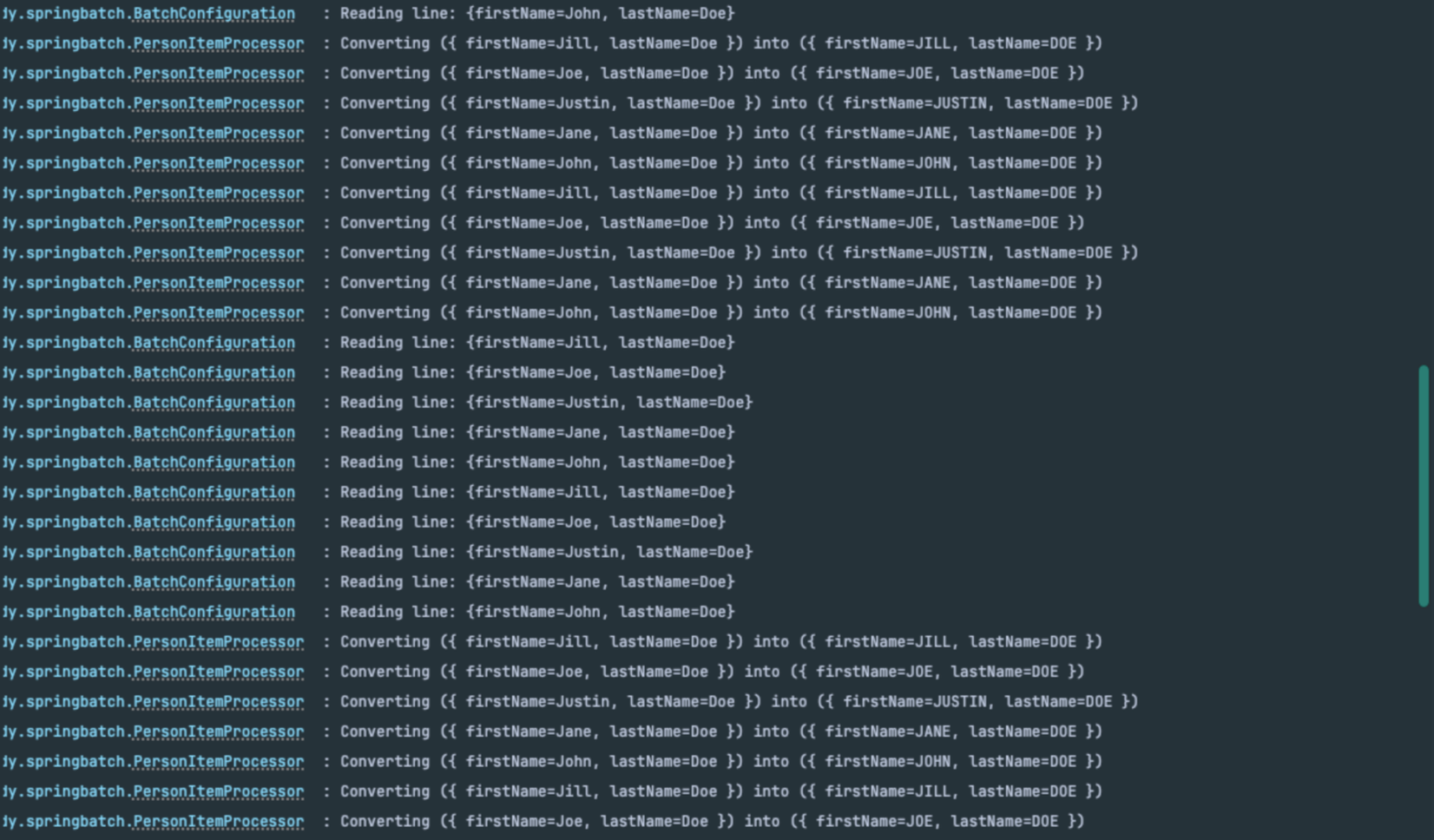
lineMapper를 수동으로 등록해서 동작시켜보면 데이터를 10개씩 읽어서 변환하는 것을 볼 수 있다.